


이 논문을 선정하게 된 배경
저는 원래 추천시스템 말고도 데이터 마이닝에 관심이 많았습니다. 글자들로부터 유의미한 데이터를 뽑아내고 가공해서 비지니스적 인사이트를 도출하는 거죠. 그래서 단어들의 군집화, 연관성 분석에도 관심이 많았는데 이 논문은 데이터 마이닝기법을 활용하여 추천서비스를 구현하였기에 신선하다고 느꼈습니다.
Introduction
우리는 너무나 정보가 많은 정보의 홍수속에서 살고 있습니다. 이러한 상황에서 필요한 정보를 찾기란 너무 어려운 일이죠. 특히나 논문검색과 같이 생소한 분야일수록 더더욱 그렇습니다. 그래서 이 논문은 데이터 마이닝 기법을 이용하여 키워들을 소셜네트워크와 같은 형태로 제시하고 사용자들에게 적절한 키워드를 추천하는 것을 목표로 하고 있습니다.
Model/Architecture
주된 개념
키워드들을 기준으로 연관 관계 분석을 하여 자주 보이는 키워드 쌍으로 도출하고 이를 네트워크 형태로 도식화하는 것을 목표로 하고 있습니다.
1.
논문별 키워드 추출
전체 DB에서 논문별 키워드를 추출하여 목록으로 만듭니다.
2.
키워드 표준화
표준용어사전을 이용하여 키워드들을 표준화 합니다. 표준 용어사전은 간단한 동의어 사전을 활용하여 구축합니다.
3.
빈발 출현 키워드 쌍추출
지지도와 신뢰도를 기준으로 동시출현 빈도가 높은 키워드 쌍을 추출합니다.
4.
전체 키워드 간 소셜 네트워크 구축
해당 연관규칙의 신뢰도가 임계값 이상인 두 노드를 간선으로 이어서 표현합니다.
5.
이용자는 검색어를 입력하여 서비스를 제공 받습니다.
<제공 과정>
•
검색어 입력
•
표준 용어 사전을 통해 표준 검색어로 변환
•
네트워크에서 검색어와 인접한 키워드를 보여주고 인접도를 함께 제시.
빈발출현 키워드쌍 추출법
•
신뢰도: X가 발생했을때 Y가 발생활 확률
Confidence =
•
지지도: X,Y가 동시에 발생할 확률
Support =
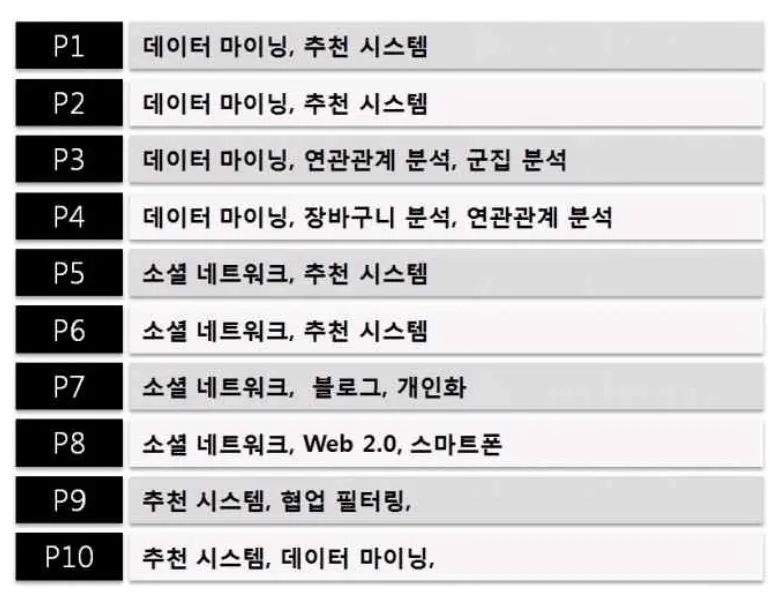
위의 예제를 통해 지지도, 신뢰도 계산하기
데이터 마이닝이라는 단어와 추천 시스템이 동시에 나올확률은
10가지 경우중 3가지이기 때문에 지지도는 30%입니다.
데이터 마이닝이라는 단어가 나왔을때 추천 시스템이 나올 확률은
5가지 경우중 3가지이기 때문에 신뢰도는 60%입니다.
6.
SAS E-miner를 통해 지지도, 신뢰도, 향상도를 계산합니다.

7.
지지도가 2%이상인 연관관계를 표현합니다.

위의 그림은 지지도가 2%이상인 연관관계를 표현한 것이고 색상은 지지도, 모양은 신뢰도, 크기는 향상도를 의미합니다.
8.
임계값을 이용해 패턴을 추출합니다.

지지도 1%이상, 신뢰도 5%이상 향상도1%이상이라는 임계값을 통해 284가지의 패턴이 발견되었고 이를 노드간의 연결정도에 따른 분포로 나타냅니다.
9.
발견된 패턴들을 노드를 이용해서 네트워크로 표합니다.
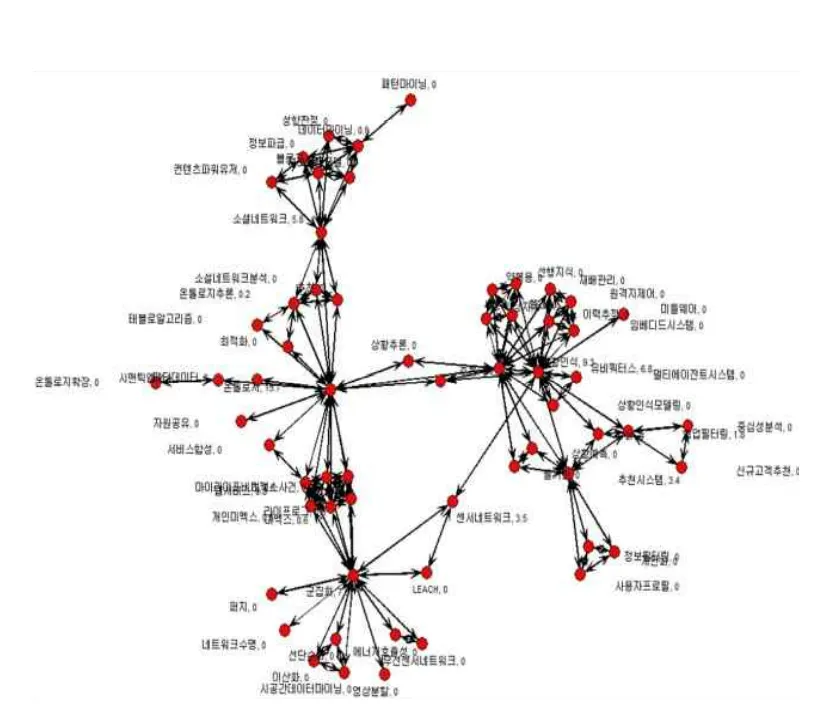
발견된 패턴들을 노드간의 연결정도에 따라 분포를 그리면 위와 같은 그림이 나옵니다. 분석결과 중심키워드는 온톨로지, 상황인식, 소셜네트워크, 군집화가 발견되었습니다.

